



一、概述
ChatGPT 是一种基于 GPT-3.5 架构的强大自然语言处理技术,最近在人工智能领域引起了极大的关注和火爆程度。这种技术是由 OpenAI 开发的,可以为开发者和企业提供高质量的自然语言交互能力。
最新的 GPT-3.5 模型比之前的模型更加出色,具有更高的语言理解和生成能力,可以为用户提供更加精确和有趣的回答。这个模型还可以学习和适应不同领域的语言和专业术语,因此可以用于许多不同的行业和应用场景。
使用 ChatGPT 的 API 可以让开发者快速集成强大的自然语言处理技术到他们的应用程序中。API 的常用玩法包括聊天机器人、智能客服、自然语言搜索引擎和自动语言翻译器等。这些应用程序可以为用户提供更加自然、流畅和智能的体验,从而提高用户满意度和效率。
二、作为程序员,我能做点什么
都说 ChatGPT 这样发展下去,就要取代程序员了。当然,我认为短时间内肯定是达不到这种程度的,所以在他要取代我们之前,我先学会如何压榨他给我打工不就好了? 我让他帮我写代码,查资料,接入 API 实现一些有意思的功能,以及,写一篇文章的开头,比如这样:

没错,第一部分的概述就是 ChatGPT 自动生成的。当然,我个人认为还是稍微有些死板,不过效果也不错了。
三、API 介绍
言归正传,本文主要是介绍如何接入 OpenAI 的接口,从而快速实现一个基于 GPT3.5 模型的聊天 demo。当然,自行研读官网的 API 文档,有些经验的程序员都能搞定。在这里只是想将接入 OpenAI 的门槛再降低一些,帮助大家更好的理解和使用。
官方接口文档:https://platform.openai.com/docs/api-reference/chat
1.API Key
当你想要调用 OpenAI 的 API 时,首先要先创建一个属于自己的 API Key,因为所有的请求都需要通过 API Key 来鉴权。
登录 platform.openai.com,访问地址:https://platform.openai.com/account/api-keys,即可创建属于自己的 key。如图所示:
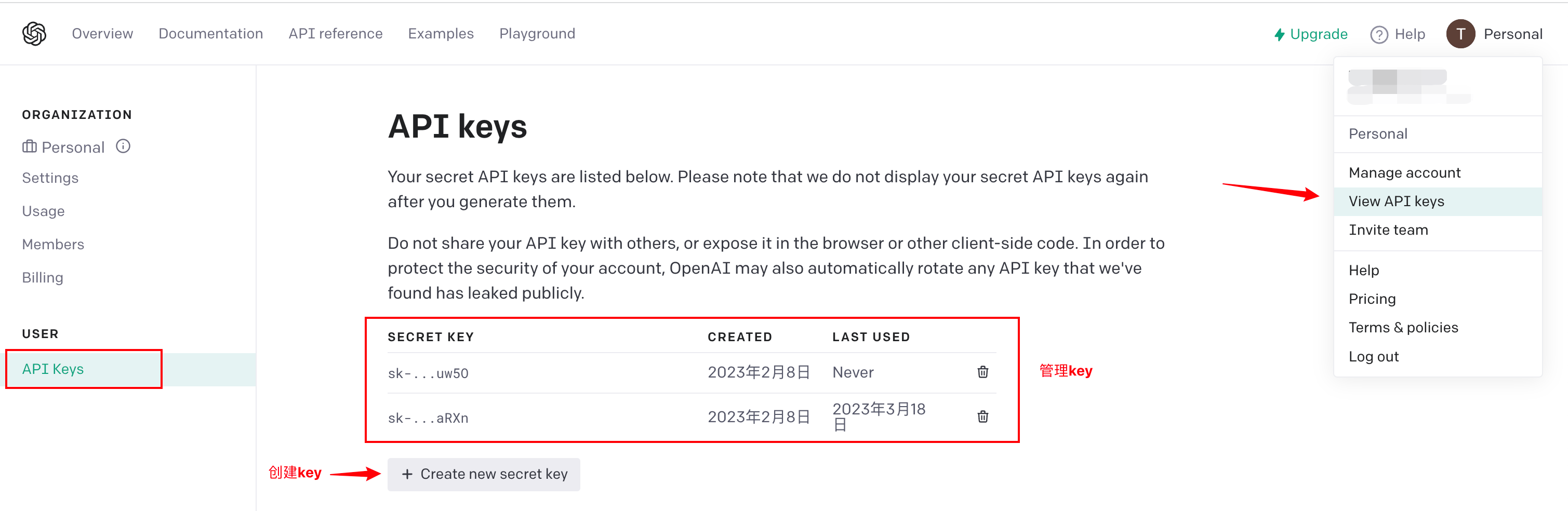
创建 key 时,需要立即复制并保存,因为 key 的信息只会展示一次,之后就看不到这个 key 的信息了。
2.请求方式
实现聊天功能其实非常简单,只需要 POST 请求这个 API 即可:https://api.openai.com/v1/chat/completions
最简单的例子
官方给出的一个最基本的 curl 的请求方式如下:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
我们可以看到,需要在请求头里配置好你的OPENAI_API_KEY,也就是上一步生成的 key。
请求体中,有两个参数:
model:本次对话选用的模型,这里使用了 gpt-3.5-turbomessages:对话信息
对于messages,这里需要多说几句。
最开始使用网页版的 ChatGPT 时,疑惑为什么后台可以记住这么多次的对话,并且每切换到一个对话上,ChatGPT 都可以联系上下文延续之前的对话。后来才知道其实每次提问时,都是将当前对话已有的全部聊天记录请求到后台,ChatGPT 会根据全部的聊天信息去分析语境,并且做后续的回答。
所以,我们在调用 API 的时候也是如此,请求中的messages是一个 JSON 数组。其中包含本次对话的全部消息。只有这样才能保证对话的连贯性。
其中:
role:代表角色,用来区分消息是谁发送的。共有三种角色:system-系统角色,可以做一些底层的配置。user-用户角色,代表是用户发的消息;assistant-助手角色,也就是 ChatGPT 返回的消息。content:消息内容
所以,当进行过几次对话后,你请求时的messages参数应该会像这样:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"content":"你是谁","role":"user"},{"content":"\n\n我是一个人工智能语言模型,被称为OpenAI的GPT-3模型。","role":"assistant"},{"content":"你是如何工作的","role":"user"},{"content":"我是由OpenAI开发的一个自然语言处理模型,使用了深度学习和人工智能技术。我从大量的数据中学习,包括文本、文章、电子邮件、社交媒体帖子等。我可以生成文本、回答问题、翻译语言和执行其他语言任务。当用户输入文本时,我会分析文本的上下文和语义,然后使用我的算法来产生响应。为了提高我的准确性和响应速度,我经常被训练和更新。","role":"assistant"}]
}'
对于messages的更多描述,感兴趣的朋友可以再多看一眼官方文档的介绍:https://platform.openai.com/docs/guides/chat/introduction
其他的重要入参
以上只是一个最基础的例子,只包含了两个必填参数——model和messages。除此之外,接口还可以传入其他的参数,在这里重点介绍几个常用的参数:
temperature:这个参数控制生成文本的随机性,取值范围在 0 到 2 之间。较高的 temperature 会导致更随机的生成结果,而较低的 temperature 则会导致更可预测的生成结果。通常情况下,值在 0.5 到 1 之间。max_tokens: 生成文本的最大长度,以词汇单位计算。这个参数控制生成文本的长度。stop: 用于控制生成文本的停止条件。这个参数是一个字符串数组,当生成文本中出现数组中任何一个字符串时,API 将停止生成。frequency_penalty和presence_penalty: 这两个参数用于控制生成文本的多样性,值的范围在 -2.0 到 2.0 之间。frequency_penalty用于控制生成文本中重复词汇的数量,而presence_penalty用于控制生成文本中出现的词汇和输入文本中出现的词汇之间的相似度。通常情况下,这两个参数的值应在 0 到 1 之间。
3.响应参数
这里直接放一段接口的响应值:
{
"id": "chatcmpl-6vJecaJmETOgIc7ZWF47wXUeqmeWU",
"object": "chat.completion",
"created": 1679118266,
"model": "gpt-3.5-turbo-0301",
"usage": {
"prompt_tokens": 11,
"completion_tokens": 28,
"total_tokens": 39
},
"choices": [
{
"message": {
"role": "assistant",
"content": "\n\n我是一个人工智能语言模型,被称为OpenAI的GPT-3模型。"
},
"finish_reason": "stop",
"index": 0
}
]
}
其中,choices内部的message是本次返回的消息,我们解析后获取这部分信息就完成本次对话啦。
usage是本次请求消耗的 token 信息。其中:
prompt_tokens是发送请求消耗的 token 数completion_tokens是响应消耗的 token 数total_tokens就是二者的总和了
Q:啥是 token?
A:
在计算机编程中,token 是指代码中的最小单元,通常是一个词、一个符号或者一个数字。在机器学习和自然语言处理中,token 通常指的是一个单词或一个词组。
在 OpenAI API 中,token 是指模型对输入文本进行分词后的结果。模型的输入是一个由 token 组成的序列,模型会根据这个序列来生成相应的输出。因此,每次调用 API 时,您需要指定生成回答的最大 token 数,以限制模型生成的文本长度。
同时,OpenAI API 使用 token 来计费。每个 API 调用需要消耗一定数量的 token,具体数量取决于模型的大小和您指定的参数。因此,在使用 OpenAI API 时,需要仔细控制每个 API 调用的参数,以最大程度地利用已经消耗的 token。
四、代码实现
其实代码实现也不难,核心逻辑就是调用 OpenAI 的 API,以及缓存每个对话的消息。同时,参数应该可配置化,且要考虑到多用户同时使用时相互隔离。
项目使用 Java 开发,jdk 版本为 1.8,使用 springboot 2.7.9 版本构建项目,http 请求使用了 okhttp3,缓存使用了 guava 的缓存组件。
1.核心逻辑,API 调用
首先,依照上文介绍的请求信息格式,构造请求头和请求体:
/**
* 初始化请求体
*
* @param msgs
* @return
*/
private Map<String, Object> getGPTRequestBody(List<GPTMessageDTO> msgs) {
Map<String, Object> body = Maps.newHashMap();
// 指定为gpt-3.5-turbo模型
body.put("model", "gpt-3.5-turbo");
body.put("messages", msgs);
body.put("max_tokens", baseConfig.getMaxTokens());
body.put("temperature", baseConfig.getTemperature());
return body;
}
/**
* 初始化请求头
*
* @return
*/
private Map<String, String> getGPTHeader() {
Map<String, String> header = Maps.newHashMap();
// 自己账户申请的APIkey
header.put("Authorization", "Bearer " + baseConfig.getChatGptApiKey());
header.put("Content-Type", "application/json");
return header;
}
使用 okhttp3 发送请求:
// 构造请求
Map<String, String> header = getGPTHeader();
List<GPTMessageDTO> msgs = getMsgs(text, fromUser);
Map<String, Object> body = getGPTRequestBody(msgs);
MediaType mediaType = MediaType.parse("application/json;charset=utf-8");
RequestBody requestBody = RequestBody.create(JSON.toJSONString(body), mediaType);
// 请求接口,并返回信息
String response;
try {
response = OkHttpUtil.post(COMPLETION_URL, requestBody, header);
} catch (Exception e) {
return "哎呀,网络不好,请稍后重试";
}
其中 OkHttpUtils 是简单封装了一下的工具类,方便在头里添加一些通用的属性。
请求后解析响应值里的数据,都是些对 JSON 格式数据的处理,这里就不多说了。
2.缓存设计
缓存是为了保存每组对话的历史聊天记录,从而保证之后聊天的顺畅性。
这里只设计了用户层级的区分,即每个用户只有一组对话,我们在缓存里保存这组对话的消息列表。
当然,如果需要支持每个用户可以开启多组对话,那就再套一层即可。
代码如下:
public class CacheUtil {
/**
* 对话缓存,key为用名,value为一组对话的历史消息列表
*/
private static final Cache<String, List<GPTMessageDTO>> CHAT_GPT_CACHE;
static {
// 设置超时时间
CHAT_GPT_CACHE = CacheBuilder.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).build();
}
/**
* 更新消息列表
*
* @param userName
* @param gptMessageDtos
*/
public static void setGptCache(String userName, List<GPTMessageDTO> gptMessageDtos) {
CHAT_GPT_CACHE.put(userName, gptMessageDtos);
}
/**
* 获取用户的消息列表
*
* @param userName
* @return
*/
public static List<GPTMessageDTO> getGptCache(String userName) {
List<GPTMessageDTO> messageDtos = CHAT_GPT_CACHE.getIfPresent(userName);
if (CollectionUtils.isEmpty(messageDtos)) {
return Lists.newArrayList();
}
return messageDtos;
}
/**
* 清空用户对应的对话缓存
*
* @param userName
*/
public static void clearGptCache(String userName) {
List<GPTMessageDTO> messageDtos = CHAT_GPT_CACHE.getIfPresent(userName);
if (CollectionUtils.isNotEmpty(messageDtos)) {
messageDtos.clear();
}
}
}
3.参数配置
将调用 API 时需要的参数放到配置文件里,方便修改:
# chatGPT配置
# 你的apiKey
chatgpt.apiKey=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
# 最大的token数
chatgpt.maxTokens=1024
# 控制生成文本的随机性,数值越高回答越随机,数值越低回答越固定。范围0-2,通常情况下,值在0.5到1之间
chatgpt.temperature=0.8
# 一次连续对话中,最大的对话次数限制,可自行修改
chatgpt.maxChatNum=15
# 是否开启连续对话
chatgpt.isContinuous=true
/**
* 基本配置,从配置文件读取
*
* @date 2023/3/17
*/
@Configuration
@Getter
public class BaseConfig {
@Value("${chatgpt.apiKey}")
private String chatGptApiKey;
@Value("${chatgpt.maxTokens}")
private int maxTokens;
@Value("${chatgpt.temperature}")
private double temperature;
@Value("${chatgpt.maxChatNum}")
private Integer maxChatNum;
@Value("${chatgpt.isContinuous}")
private boolean isContinuous;
}
4.请求
在 controller 层提供一个 POST 接口,就可以使用啦
@RestController
@Slf4j
public class ChatGptController {
@Autowired
private ChatGPTService chatGptService;
@PostMapping("/chat")
public String receiveMsgFromDd(@RequestBody ChatRequestVO chatRequestVO) {
return chatGptService.chatToGPT(chatRequestVO.getContent(), chatRequestVO.getUserName());
}
}
五、常见问题
1. 价格
本文使用的 gpt-3.5-turbo 模型价格为$0.002 / 1K tokens,相比于上一代的 Davinci 模型确实是便宜了 90%。所以注册账户赠送的 18 美元可以称得上是肆无忌惮的使用都不怕了。
自己账号的消费情况,可以在这个链接看到:platform.openai.com
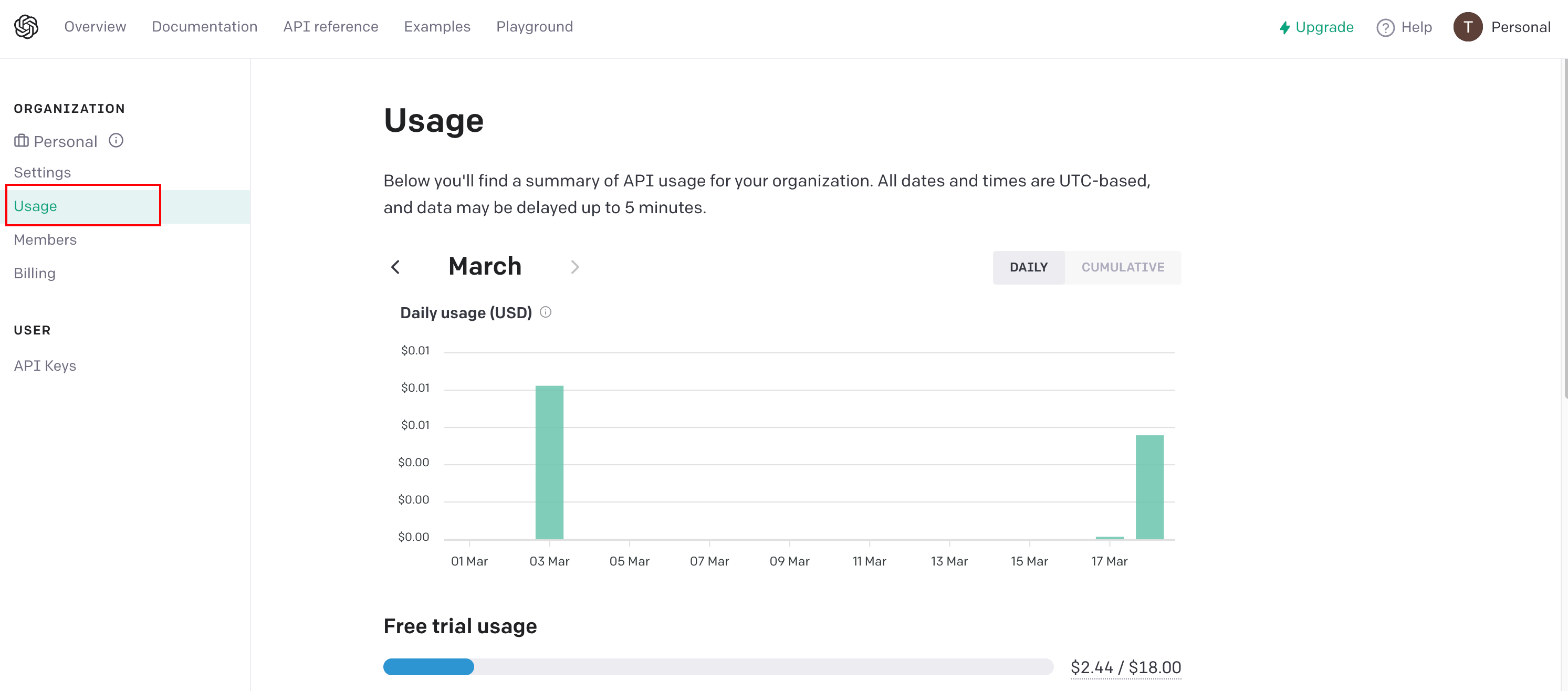
今天真是折腾了好久,连一分钱都没用完。而下面的两美元都是 2 月份时用上代模型自己往群里接机器人时,几个人扯扯淡给用没的……
而完整的资费信息,官网链接在此:https://openai.com/pricing
2.如何降低费用
当然,钱也不是大风刮来的,能省则省。而当一个对话产生了多条消息后,每次的请求都会占用大量的 token。token 就是钱!所以降低费用的方式就是避免过多地消耗 token,我们可以使用以下方法来优化对话:
- 限制对话长度:可以设置对话的最大长度,以避免生成过多的文本。在生成下一句话之前,检查对话历史记录的长度是否超出了限制。如果超出了限制,可以结束对话或清空历史记录并重新开始。
- 优化对话历史记录:尽量避免将无关或冗长的文本包含在对话历史记录中。其实我们也不好判断哪些是冗长的文本,所以可以采用固定大小队列的方式保存消息,即只保留最近几条消息作为请求,以提供可控数量的上下文信息。
本文对应的程序采用了第一种方法,即在接口返回结果时,判断消息列表是否超长,是则清空列表,否则继续将本条消息追加到列表中。
六、总结
本文介绍了 OpenAI 聊天 API 的接入方式、各个参数的含义以及核心功能的代码实现。希望能够帮助大家“即便不看官方文档也可以轻松快速的实现 API 接入的开发”。
彩蛋时间
免费的ChatGPT体验网站,分享给大家:http://chatgpt.esparks.cn/
评论区